

Optical Character Recognition (OCR) represents one of the most enduring and transformative technologies in the history of computing. What began as a simple machine to convert text into telegraph code has evolved into sophisticated AI systems capable of understanding context, analysing document layouts, and extracting meaning from the most complex business documents.

This journey spans over a century of innovation, from mechanical devices to neural networks, fundamentally changing how we interact with printed and digital information.
Today, OCR technology processes billions of documents daily, powering everything from mobile banking apps to enterprise automation systems. Yet despite its ubiquity, many still underestimate its complexity and potential.
This comprehensive exploration traces OCR’s remarkable evolution, examines its current capabilities and limitations, and peers into a future where intelligent document processing becomes indistinguishable from human comprehension.
The Genesis: Telegraph Roots and Early Innovations (1914-1950s)

The Goldberg Foundation
The story of OCR begins in 1914, during World War I, when physicist Emanuel Goldberg invented a machine that could read characters and convert them into telegraph code. This wasn’t merely a technological curiosity—it was a practical solution to a real communication problem.
At the time, telegraphs were the fastest form of long-distance communication, and automating the conversion of printed text to telegraph signals represented a significant efficiency gain.
Goldberg’s ambitions extended far beyond simple character recognition.
In the 1920s, he developed what he called a “Statistical Machine”—arguably the first electronic document retrieval system.
This system addressed a growing business challenge: companies were microfilming financial records for storage, but retrieving specific documents from spools of film was nearly impossible.
Goldberg’s solution used a photoelectric cell for pattern recognition, essentially repurposing movie projector technology for document management.
The significance of Goldberg’s work cannot be overstated. His 1931 U.S. Patent number 1,838,389 was later acquired by IBM, laying the groundwork for decades of development in automated document processing.
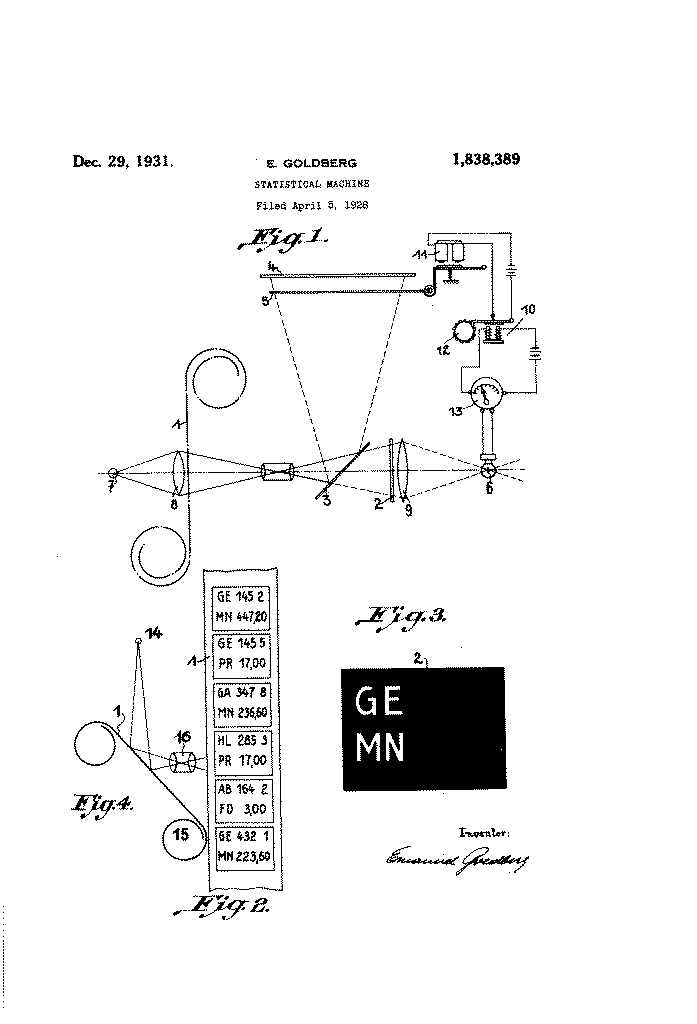
This early recognition of OCR’s potential established a foundation that would support the entire industry.
The Assistive Technology Connection
Interestingly, some of the earliest OCR development was driven by accessibility needs.
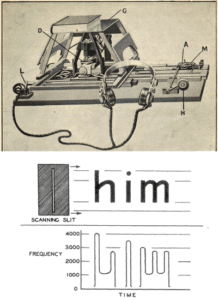
The Optophone, demonstrated in 1921, allowed blind users to “read” printed text by converting it into musical chords. Though primitive by today’s standards—achieving a reading speed of just one word per minute—it represented a crucial proof of concept for machine-assisted reading.
This connection between OCR and assistive technology would prove prophetic. Many of the most significant advances in OCR, including Ray Kurzweil’s later innovations, were initially motivated by the desire to help visually impaired individuals access printed information.
The Digital Dawn: Early Computer-Based OCR (1950s-1970s)

IBM’s Standardisation Effort
In 1959, IBM introduced a brand-new system for capturing data from documents and formally named it “Optical Character Recognition,” establishing the standard terminology that persists today. This wasn’t just a naming convention—it represented IBM’s commitment to developing OCR as a core computing technology.
The 1960s marked a turning point when MIT established dedicated research groups to enhance OCR software capabilities. These researchers were remarkably prescient, developing sophisticated algorithms that could analyse data and adapt to changing document formats. However, they were limited by the computational power available at the time. Unknowingly, they were on the verge of introducing machine learning to OCR—a breakthrough that would have to wait several decades.
Practical Applications Emerge
The 1960s saw the first real-world OCR applications. Reader’s Digest built an OCR document reader to digitize serial numbers from coupons returned from print advertisements, demonstrating OCR’s commercial viability. Meanwhile, postal services began experimenting with OCR for mail sorting based on ZIP codes—an application that would eventually transform mail processing worldwide.
The Font Revolution
In 1968, Swiss typeface designer Adrian Frutiger developed OCR-A, the first optically machine-readable font. This specialized typeface was designed specifically for machine readability, featuring distinctive character shapes that early OCR systems could reliably distinguish. The development of OCR-A highlighted a crucial limitation of early systems: they could only process text in fonts specifically designed for machine reading.

The Kurzweil Era: Breakthrough and Commercialization (1970s-1990s)

In 1974, Ray Kurzweil founded Kurzweil Computer Products, Inc., and developed the first omni-font OCR system—a computer program capable of recognizing text printed in virtually any font. This breakthrough eliminated the need for specialized fonts and opened OCR to a vastly broader range of documents.
Kurzweil’s innovation extended beyond technical capability. He created the first complete OCR system, incorporating a CCD flatbed scanner and text-to-speech synthesizer. On January 13, 1976, this reading machine for the blind was unveiled at a widely reported news conference, demonstrating OCR’s potential to transform accessibility.

Commercial Success and Industry Growth
In 1978, Kurzweil Computer Products began selling commercial OCR software, with LexisNexis as one of the first major customers, using the technology to upload legal documents and news articles to their nascent online databases. This marked the beginning of OCR’s integration into mainstream business operations.
The commercial success led to rapid industry consolidation. In 1980, Kurzweil sold his company to Xerox, which later spun it off as Scansoft, eventually merging with Nuance Communications. This corporate evolution would shape the OCR industry for decades to come.
Desktop Revolution
During the 1980s, OCR technology became widely used for digitizing print documents, particularly in libraries and offices. The development of desktop publishing and personal computers created new demand for OCR capabilities, leading to the creation of consumer-friendly OCR software.
In the 1990s, companies like Caere Corporation introduced OmniPage, one of the first OCR programs designed for personal computers. This democratization of OCR technology extended its reach far beyond enterprise applications, making document digitization accessible to small businesses and individual users.
The Digital Integration Era (1990s-2000s)

Internet and Mobile Integration
In the 2000s, OCR became available online as a service (WebOCR), operating in cloud computing environments and mobile applications. This shift from desktop software to web-based services reflected broader trends in software delivery and consumption.
The integration of OCR into mobile devices proved particularly transformative. With the advent of smartphones, OCR enabled real-time translation of foreign-language signs and automatic text extraction from camera captures. This mobile integration brought OCR capabilities to billions of users worldwide, far exceeding the reach of traditional desktop applications.
The Google Books Project
Google’s launch of Google Books (code-named Project Ocean) represented one of the most ambitious OCR projects ever undertaken, digitizing tens of millions of books and making their text searchable. This project demonstrated OCR’s potential for large-scale digitization while also raising important questions about copyright and access to information.

The Google Books project pushed OCR technology to handle an unprecedented variety of documents, from centuries-old manuscripts to modern publications. This diversity of source material drove improvements in OCR accuracy and robustness.
The AI Revolution: Deep Learning Transforms OCR (2010s-Present)

Neural Networks Enter the Scene
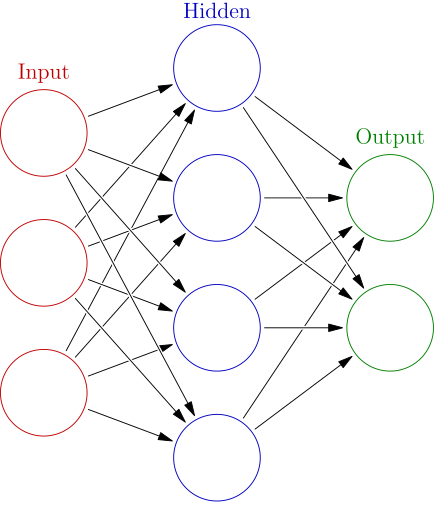
In 2018, Google launched Tesseract 4.0, incorporating deep learning-based text recognition using LSTMs (Long Short-Term Memory networks). This marked a major technological leap in OCR, as deep learning and neural networks dramatically improved recognition of handwritten text and complex layouts.
The adoption of deep learning represented a fundamental shift in OCR architecture. Traditional OCR systems relied on rule-based pattern matching, while neural networks could learn to recognize patterns through training on vast datasets. This change enabled OCR systems to handle previously challenging scenarios, such as cursive handwriting, degraded documents, and unusual fonts.
Multi-Modal AI Integration
Modern AI-powered OCR systems use convolutional neural networks (CNNs) for visual pattern recognition and recurrent neural networks (RNNs) for understanding text sequences and context. This combination allows systems to process both structured and unstructured data with unprecedented accuracy.
The integration of computer vision and natural language processing has created OCR systems that don’t just recognize characters—they understand document structure, context, and meaning. These systems can analyse segmented parts of images, recognizing patterns and features in text while being trained on vast arrays of fonts, handwriting styles, and languages.
Current Accuracy Achievements
Current OCR tools can achieve beyond 99% accuracy on typewritten texts, representing a dramatic improvement over earlier systems. However, this high accuracy comes with important caveats. While all major OCR engines achieve exceptional accuracy rates above 99% on webpage screenshots, handwritten and scanned document recognition remains more challenging, with some systems struggling with error rates above 10% on difficult handwriting.
The variation in accuracy across different document types highlights OCR’s continuing evolution. Google Cloud Vision has emerged as a leader in challenging recognition scenarios, while traditional systems like Tesseract show higher error rates on scanned documents, suggesting that historical OCR algorithms don’t compete effectively against modern deep learning techniques.
While general OCR systems achieve 99% accuracy on standard documents, specialized applications require even higher precision.
For Indian businesses, this challenge is particularly acute due to GST compliance requirements, mixed English-Hindi text, and complex invoice formats.
DocXtract addresses these specific challenges by combining multiple AI models trained specifically on Indian business documents.
Unlike generic OCR solutions, DocXtract understands GST structures, HSN codes, and tax calculations, achieving 98%+ accuracy on real Indian invoices rather than clean test datasets.

Current State: Capabilities and Limitations
Technical Architecture
Modern OCR systems employ sophisticated multi-stage processing pipelines. The process begins with image acquisition, where documents are converted to black-and-white versions and analysed for light and dark portions. Preprocessing then cleans the digital image, removing noise and correcting alignment issues.
Text recognition occurs through two primary methods: pattern recognition, where characters are compared against trained templates, and feature recognition, which applies rules about character features when processing unknown fonts. The choice between these approaches depends on the complexity and variability of the source documents.
Intelligent Character Recognition (ICR)
Advanced systems now incorporate Intelligent Character Recognition (ICR), leveraging AI to learn continuously through practice and training. Neural networks analyse text repeatedly, identifying distinctive attributes like curves, intersections, lines, and loops. This approach mimics human reading processes, enabling systems to handle documents that would challenge traditional OCR.
Multi-Modal Processing
Modern OCR recognises that business documents aren’t just text—they’re visual information systems. Table layouts convey data relationships, logo positions indicate document sections, and signature placements validate authenticity. This understanding has led to multi-modal AI systems that process text, images, and layout simultaneously.
Current Limitations
Despite significant advances, OCR faces persistent challenges. Companies still require human intervention to check for potential errors, and the current focus of OCR research is primarily on handwriting recognition and cursive text recognition. Poor image quality, unusual fonts, and complex layouts continue to challenge even the most advanced systems.
Among the products benchmarked in recent studies, only a few could output successful results across all test scenarios, indicating that no OCR product can recognize all kinds of text with 100% accuracy.
This understanding has led to multi-modal AI systems that process text, images, and layout simultaneously.
Modern solutions like DocXtract exemplify this approach, using context-aware processing to understand not just individual characters, but complete business workflows—recognizing that Indian invoice processing requires understanding of regulatory compliance, not just text extraction.
Industry Applications and Impact
Financial Services
OCR has transformed financial document processing, enabling automated check deposits, invoice processing, and compliance documentation. In banking, OCR automates customer verification, check deposits, and other processes through text extraction and verification. The technology has reduced processing times from days to minutes while improving accuracy and reducing costs.
For Indian businesses specifically, invoice processing presents unique challenges due to GST compliance requirements.
Solutions like DocXtract demonstrate how specialized AI can address these needs, processing invoices with multiple tax components, HSN codes, and regulatory validation in minutes rather than hours.
Healthcare
Healthcare applications include processing patient histories, X-ray reports, and diagnostic reports. OCR has enabled the digitization of decades of paper medical records, making patient information more accessible and supporting better clinical decision-making.
Insurance and Legal
Insurance companies use OCR to extract text information from various documents, while legal firms digitize contracts, case files, and regulatory documents. These applications have dramatically reduced manual data entry while improving document searchability and accessibility.
Enterprise Document Management
Modern enterprises use OCR for comprehensive document automation. Organizations digitize printed texts for electronic editing, searching, compact storage, and online display, supporting machine processes like cognitive computing and machine translation.
The Future: AI-Powered Intelligence
Multimodal Large Language Models
The emergence of multimodal LLMs like GPT-4, Claude 3, and Gemini represents a fundamental shift in OCR capabilities. These models can rival or exceed traditional OCR accuracy, with some studies showing that top LLMs significantly outperform state-of-the-art OCR models on difficult handwriting tasks.
Unlike traditional OCR systems that require separate text detection and recognition steps, multimodal LLMs can understand document context directly, answering questions about content without explicit OCR processing. This represents a move toward true document understanding rather than simple character recognition.
Self-Supervised Learning
Self-supervised pretraining techniques are revolutionizing OCR development. Instead of relying solely on costly labelled data, OCR models are being pre-trained on large volumes of unlabelled text images, yielding significant accuracy improvements, especially for handwriting recognition.
Context-Aware Processing
Future OCR systems will understand not just what text says, but what it means in business context. Systems will interpret complex legal and medical documents, extract sentiment and tone, and understand document hierarchy and relationships.
Edge Computing Integration
OCR is moving toward edge processing, enabling real-time document processing without internet connectivity, enhanced privacy through local data processing, and reduced latency for time-sensitive applications. This shift addresses growing concerns about data privacy and system reliability.
Vision-Language Foundation Models
The future will see models specifically pretrained on millions of document images with their text, creating “GPT for documents” that understand layout semantics deeply. These models will perform document classification, segmentation, and OCR in unified workflows.
Unlike traditional OCR systems that require separate text detection and recognition steps, multimodal LLMs can understand document context directly, answering questions about content without explicit OCR processing.
This context-aware approach is already being implemented in specialized applications. DocXtract represents this evolution, using multiple AI models that adapt based on document complexity—employing LLMs for complex reasoning about tax calculations while using specialized models for layout understanding, demonstrating how the future of OCR lies in intelligent model selection rather than one-size-fits-all solutions.
Challenges and Considerations
The Accuracy Plateau
While current OCR tools achieve remarkable accuracy on standard documents, higher accuracy levels are still desired as companies continue to rely on human intervention for error checking.
The remaining accuracy gaps, particularly in challenging scenarios like handwritten documents, represent significant technical and business challenges. Regional specialization compounds these challenges.
While global OCR solutions optimize for Western document formats, markets like India require understanding of local business practices, multilingual text, and regulatory requirements.
This has led to the development of region-specific solutions like DocXtract, which prioritizes Indian business document accuracy over broad international coverage.
Ethical and Privacy Concerns
As OCR systems become more capable, they raise important questions about privacy and data security. The ability to automatically extract and analyse vast amounts of textual information creates new possibilities for surveillance and data mining that require careful consideration.
Integration Complexity
While AI-powered OCR systems offer superior accuracy and capabilities, they also require more sophisticated integration approaches compared to traditional OCR systems. Organizations must balance the benefits of advanced capabilities against the complexity of implementation and maintenance.
Cost and Resource Requirements
Advanced AI-powered OCR systems require significant computational resources and ongoing maintenance. The evolution toward more sophisticated systems means organizations must carefully consider the total cost of ownership, including hardware, software, and skilled personnel requirements.
Looking Forward: The Next Decade
Unified Document Intelligence
The future of OCR lies not in isolated text recognition, but in comprehensive document intelligence. OCR will become a gateway to end-to-end automation, with systems capable of understanding business intent rather than simply extracting text.
Predictive and Prescriptive Analytics
Future OCR systems will incorporate predictive analytics based on document patterns, automated business rule enforcement, intelligent routing based on content analysis, and proactive compliance monitoring. This evolution transforms OCR from a reactive technology to a proactive business intelligence tool.
Seamless Integration
The ultimate vision for OCR is seamless integration with everyday business processes, where document processing becomes invisible and automatic, freeing human intelligence for higher-value activities.
Global Accessibility
Improvements in OCR for low-resource scripts and languages will democratize access to document processing capabilities, supporting global business operations, and reducing barriers to information access.
Conclusion
OCR technology’s century-long journey from telegraph code conversion to AI-powered document intelligence represents one of the most remarkable success stories in computing history. What began as a simple mechanization of text recognition has evolved into sophisticated systems capable of understanding context, meaning, and business intent.
The transformation from rule-based pattern matching to neural network-based understanding represents more than technical progress—it reflects a fundamental shift in how machines interact with human-created information. Modern OCR systems don’t just read text; they comprehend documents, understand structure, and extract meaning.
As we look toward the future, OCR technology stands at another inflection point. The integration of large language models, multimodal AI, and context-aware processing promises to eliminate the final barriers between human and machine document understanding. The next decade will likely see OCR systems that not only match human reading accuracy but exceed human capabilities in speed, consistency, and analytical depth.
For businesses, this evolution presents both opportunities and challenges. The companies that successfully integrate advanced OCR capabilities into their operations will gain significant competitive advantages through improved efficiency, reduced costs, and enhanced decision-making.
Solutions like DocXtract demonstrate how specialized AI can deliver immediate ROI by addressing specific market needs rather than generic document processing.
The ultimate promise of OCR technology is not just automation, but augmentation—systems that enhance human capabilities rather than simply replacing human effort. As OCR continues to evolve, it will play an increasingly central role in how organizations capture, process, and derive value from the vast amounts of textual information that drive modern business operations.
The journey from Goldberg’s telegraph converter to today’s AI-powered document intelligence systems is far from over. As we stand on the brink of even more sophisticated capabilities, OCR technology continues to redefine what’s possible in the digital transformation of human information processing. The next chapter in this remarkable story promises to be the most exciting yet.


