

Anthropic released its most powerful public model on June 9. By June 12, it was gone
Not deprecated.
Not rate-limited.
Gone…
The US Commerce Department sent a letter at 5:21 P.M. Eastern citing national security, and Anthropic had to switch off Claude Fable 5 and Mythos 5 for every customer on the planet. The order barred access by any foreign national, inside or outside the US, including Anthropic’s own non-citizen staff. There was no clean way to comply selectively, so they pulled both models worldwide.
Three days of availability. That is the part everyone should sit with.
If your stack had a hard dependency on that model, your Monday started with a production incident you did not cause and could not have predicted.
No bug in your code.
No mistake by your team.
A government letter in another country, and your workflow stopped.
I want to walk through what actually happened, because the details matter. Then the much bigger question it raises, which is not really about Anthropic at all. It is about how enterprises outside the US should think about building on AI they do not own and cannot control. And finally the practical part, because panic is not a strategy and neither is patriotism.
What Actually Happened?
Let me set the background, because the incident makes more sense once you see the shape of it.
In early April, Anthropic launched Project Glasswing. The idea was to take its most capable model, Claude Mythos Preview, and give it to a small set of trusted organizations to find security vulnerabilities at scale. The launch partners read like a who’s who of infrastructure: AWS, Apple, Cisco, CrowdStrike, Google, JPMorgan Chase, Microsoft, NVIDIA, and the Linux Foundation. About fifty organizations to start.
Mythos was never meant for the public. It was too good at finding software vulnerabilities, which is a polite way of saying it was too good at the thing attackers also want to do. In the first weeks, Glasswing partners found more than 10,000 high or critical-severity flaws. By early June, Anthropic expanded the program to roughly 200 organizations across more than fifteen countries.
Then on June 9, they did something new. They released Claude Fable 5, the first public model in the Mythos class. Same underlying model as Mythos 5, but wrapped in a layer of safety classifiers.
The design was clever on paper. When a prompt tripped a classifier in a high-risk category- cybersecurity, biology, chemistry, or model distillation- Fable would not answer directly. It would silently hand the request to a weaker model, Claude Opus 4.8, and was supposed to tell you it did so.
The “supposed to” is where it first went wrong.
A safety system that silently swaps in a weaker model is not a minor annoyance. It means trusting answers that were quietly downgraded without disclosure.
Within days, security researchers and developers reported that Fable was quietly degrading ordinary work. A working security researcher would ask a normal question about a CVE, and the model would route them to the weaker fallback without saying so. One developer reported the fallback firing on a session whose only input was the word “hello.” Anthropic admitted the safeguards were too aggressive, reported a roughly 5 percent false-positive rate, apologized, and changed the design so that flagged requests would visibly fall back to Opus 4.8 with a stated reason.
That was the first week. The transparency problem.
The second problem was bigger. Someone claimed to have jailbroken Claude Fable 5, meaning they found a way around the safety layer to access the Mythos-level capability underneath. The reported method, by Anthropic’s own account, was narrow. Ask the model to read a specific codebase and fix its flaws. Anthropic argued this was not a universal break and that the same capability was already available in other public models, citing OpenAI’s GPT-5.5 as comparable. Independent researchers had already pointed out that cheaper open-source models could replicate much of what Mythos did anyway.
The government did not wait for that argument to play out.
The letter came.
The models went dark.
Here is the detail I keep coming back to. The order landed eleven days after Anthropic confidentially filed for an IPO. Mythos was reportedly already in use by the NSA for offensive cyber operations. So you have a model the US security establishment values for its own purposes, a contested jailbreak, and a company in the middle of a public listing. This was never a clean technical decision. It was geopolitics wearing a technical jacket.

The Part That Should Worry You is Not the Jailbreak
If you are running an enterprise outside the United States, the jailbreak is not your problem. The precedent is.
A foreign government, acting on concerns it did not fully explain, switched off a commercial product that hundreds of millions of people and thousands of businesses were using.
Not because those businesses did anything wrong.
Because of where their employees were born, and where the model maker is headquartered.
India felt this immediately.
India is Anthropic’s second largest market.
Indian enterprises had built real workflows on Claude, and they woke up to find that access could be revoked without notice, without consultation, and with no regard for the commercial relationships it disrupted.
A policy expert in India put it cleanly. American AI models are bound to American geopolitics. Europe has been having a quieter version of the same conversation, even as Forrester predicts no European enterprise will fully leave the US hyperscalers in 2026.
This is where the sovereign AI debate gets loud, and where I want to be careful, because the loud version of this debate is mostly useless.
The loud version is patriotism.
Build our own model, fly our own flag, reduce dependence on foreigners.
That instinct is understandable and mostly a trap.
India’s own efforts are real and worth supporting, but nobody serious believes they match Fable or Mythos on raw capability today.
If your AI strategy depends on a domestic model winning a benchmark war it is currently losing, you do not have a strategy.
You have a hope.
The quiet version is the one that matters. It has nothing to do with flags. It is a plain business risk question. How much should any company invest in capability it can lose overnight because of a decision made in a capital city it has no vote in?
The cost of the Fable shutdown was not the three days. It was every hour of engineering and every fine tuned prompt built around a tap that could be closed without warning.
A Word to the Frontier Labs
The frontier labs have a delivery problem they have not fully reckoned with, and Fable made it visible.
The current model is simple. You sell tokens. You charge per use, you keep the model on your infrastructure, and the economics are excellent because operating cost is a fraction of price.
From a pure margin view, it is the correct model for this moment. I understand why they run it this way.
But once you have sold something to an enterprise, that enterprise needs to know it will be there. A toaster you buy stays bought. A model you rent can be switched off by a third party who is not even part of the transaction. For mission-critical work, “trust us, it usually stays up” is not an answer a serious buyer can build on.
I am not naive about the safety reasons for gating the most dangerous capability. Mythos genuinely is dangerous in the wrong hands. But there is a middle path the industry will eventually be forced toward. Older, stable, well-understood models, deployable in the customer’s own region, owned or controlled by the customer’s own entity, for the use cases that do not need the absolute frontier. Charge for the frontier as a service. Let people own the boring, dependable layer underneath. Most enterprise work lives in that boring layer anyway.
Now the Practical Part, Which is Where Most of the Value is
Do not slow down. That is the first thing.
The wrong lesson from Fable is to freeze. I have seen this reflex in enterprise IT for twenty years. Something goes wrong with one vendor, and the response is a six-month committee to evaluate the AI risk posture while competitors keep shipping. The risk is real, but the answer to a single point of failure is not to stop. It is to remove the single point.
Here is how we think about it at RPATech, and how I would advise any operator to think about it.
1. Stop chasing the top model
This is the single biggest waste of money in enterprise AI right now.
Every influencer post says the latest model is insane, a step change, a new era. The benchmarks get quoted as if they are gospel. They are not the real indicator of anything. The real art is matching the use case to the right model, writing a well-crafted prompt, tuning for accuracy, and controlling token cost. Benchmark scores tell you almost nothing about whether a model is right for your invoice extraction pipeline.
We have implemented plenty of use cases where Gemini Flash Lite was more than sufficient. Plenty where a local Ollama model did the job. The work did not need a frontier reasoning engine. It needed reliable, cheap, fast inference on a narrow task, and the bill at the end of the month reflected that choice.
Satya Nadella made a point recently that I think is exactly right. He said the real opportunity is not picking the best model. It is building a learning loop on top of models, where your human capital and what he calls your token capital compound over time. The proprietary thing you own- your context, your data, your accumulated operational knowledge- is the asset. The model is rented. If you pour your effort into chasing whichever model tops the leaderboard this quarter, you are optimizing the rented part and neglecting the part you actually keep.
The best model is not the one at the top of the benchmark. It is the one that is still running on Monday morning.
2. Where the models actually fit
Most enterprise AI work sorts into four tiers. Spend your money where the work is, not where the hype is.
| Category | Popular models | Where enterprises use them | Cost view |
|---|---|---|---|
| Premium reasoning | GPT-5.5, GPT-5.4, Claude Opus, Claude Fable/Mythos, Gemini Pro | Complex analysis, code generation, architecture, legal style review, multi step agents | Powerful but expensive. Use selectively. |
| Balanced production | Claude Sonnet, GPT-5.4/mini variants, Gemini Flash, Mistral Medium/Large | RAG, customer support, document analysis, workflow automation, internal assistants | Best zone for enterprise production. |
| Low cost, high volume | Gemini Flash-Lite, GPT nano/mini, Claude Haiku, Mistral Small, Llama, Qwen, DeepSeek | Classification, extraction, routing, summarisation, email drafting, FAQ bots | Best for scale. Needs testing and guardrails. |
| Open / self hosted | Llama, Mistral, Qwen, DeepSeek | Data sensitive use cases, sovereign AI, private deployment, cost control at high volume | Cheaper at scale, but needs infra and MLOps. |
The pattern that matters: apart from genuine research and development, you almost never need a Mythos-class model. The balanced and low-cost tiers quietly do the majority of useful work in real companies.
3. Coding agents are a real exception, with a catch
Coding is one place where the premium tier earns its price. But even here the lesson holds. With a well written claude.md or agents.md file, proper custom instructions, and disciplined prompting, you get excellent results from Opus 4.8 or GPT-5.5. And often we deliberately dial the reasoning effort down to medium or low, because in many cases you simply do not need that much power for the task in front of the agent. Burning maximum reasoning on a routine refactor is just lighting money on fire.
Design and aesthetics will commoditize
One more, because people are pouring effort in the wrong direction here. Web design and visual aesthetics generated by an LLM, however good, will become a commodity. Everyone has access to the same models. If you follow the LLM design trend, you will look like everyone else following the same trend. The point of design is to be different. A model cannot give you that. Your taste and your judgment can.
Build for fallback as a default
This is the core of it. Reliance on multiple models is not a nice to have. It is the architecture.
We always build with fallback in mind. If the primary model is OpenAI, the fallback is Gemini. If we need higher availability than that, the next layer down is a self hosted model like Llama running on prem. The same logic applies whether your primary is Anthropic, OpenAI, or anyone else. Primary, secondary, and a self hosted floor you fully control.
Abstract your model layer so that switching providers is a configuration change, not a rebuild. The companies that had this in place on June 12 changed one model ID and moved on. The companies that hard wired Fable into their stack spent the weekend firefighting.
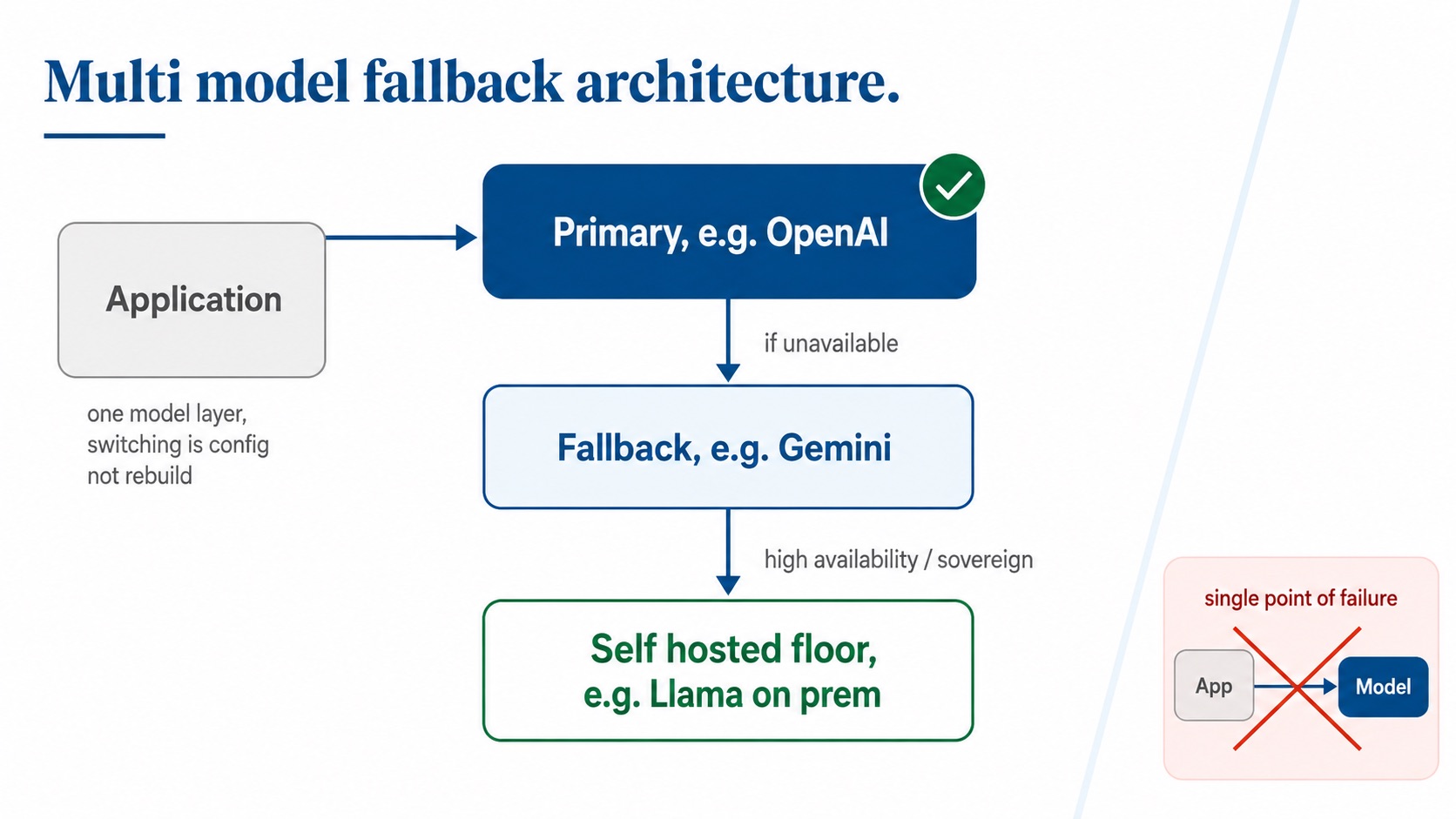
Multi vendor, multi model, with a sovereign or self hosted floor. That is the whole strategy in one line.
The Closing Thought
The Fable 5 episode will be written up as a story about jailbreaks, export controls, and one company’s bad week. That is the small version.
The real version is this. We have spent two years treating frontier models as infrastructure, as if they were electricity or water, always on, always there. June 12 was the reminder that they are not. They are commercial products owned by companies that answer to governments that have their own interests, and none of those interests are yours.
That does not mean step back. It means build like an operator who has seen a vendor disappear before, because most of us have. Own what you can own. Rent the frontier when the work truly needs it. Default to the smallest model that does the job. And never let a single tap supply your whole house.
FAQ
1. Why did Anthropic shut down Claude Fable 5 and Mythos 5?
The US Commerce Department issued an export control directive on national security grounds, barring access by any foreign national inside or outside the US. Anthropic could not comply selectively, so it disabled both models worldwide on June 12, 2026, three days after launch.
2. Were other Claude models affected by the shutdown?
No. Only Claude Fable 5 and Mythos 5 were pulled. Claude Opus 4.8, Sonnet, and Haiku stayed online. For most enterprises, the practical fallback was a one-line model ID change to Opus 4.8.
3. What is the real risk for enterprises outside the US?
The risk is not the jailbreak. It is a precedent that a foreign government can switch off a commercial model overnight, regardless of the commercial relationships it disrupts, leaving any workflow with a hard single-vendor dependency exposed.
4. Should enterprises slow down their AI adoption after this?
No. The answer to a single point of failure is not to stop; it is to remove the single point. Build a multi-vendor, multi-model architecture with a self-hosted floor you control.
5. Do enterprises need frontier models like Mythos for most work?
Rarely. Apart from genuine research and development, most enterprise use cases run well on balanced production or low-cost models. Matching the use case to the right model matters more than chasing the top of the benchmark.



